
Meta AI Launches Segment Anything Model 2 (SAM 2): Promptable Segmentation for Images and Videos
Enhance Your Writing with WordGPT Pro
Write Documents with AI-powered writing assistance. Get better results in less time.
Try WordGPT FreeBuild your custom chatbot with BotGPT
You can build your customer support chatbot in a matter of minutes.
Get StartedMeta AI has unveiled the Segment Anything Model 2 (SAM 2), a revolutionary promptable foundation model for both image and video segmentation. Building on the success of the original SAM, SAM 2 offers enhanced real-time segmentation capabilities, supporting diverse applications without the need for custom adaptations. With the release, Meta AI also introduces the SA-V dataset, comprising approximately 51,000 real-world videos and over 600,000 masklets. SAM 2 is poised to drive innovation across various fields by enabling accurate and efficient object segmentation in previously unseen visual domains.
Key Takeaways
- Unified Model: SAM 2 supports real-time, promptable object segmentation in both images and videos, achieving state-of-the-art performance.
- Open Source: Meta is releasing SAM 2 under an Apache 2.0 license, sharing code and model weights.
- SA-V Dataset: Includes ~51,000 real-world videos and over 600,000 masklets, available under a CC BY 4.0 license.
- Versatile Applications: SAM 2 segments objects in previously unseen visual domains without custom adaptation, unlocking diverse use cases.
Introduction
Meta is proud to introduce the Segment Anything Model 2 (SAM 2), the next generation in object segmentation for both images and videos. SAM 2 is available under an Apache 2.0 license, allowing broad use and experimentation. Additionally, Meta is sharing the SA-V dataset under a CC BY 4.0 license, along with a web-based demo showcasing SAM 2’s capabilities.
Key Features
Demonstration Video
Watch the video to see SAM and SAM 2 in action:
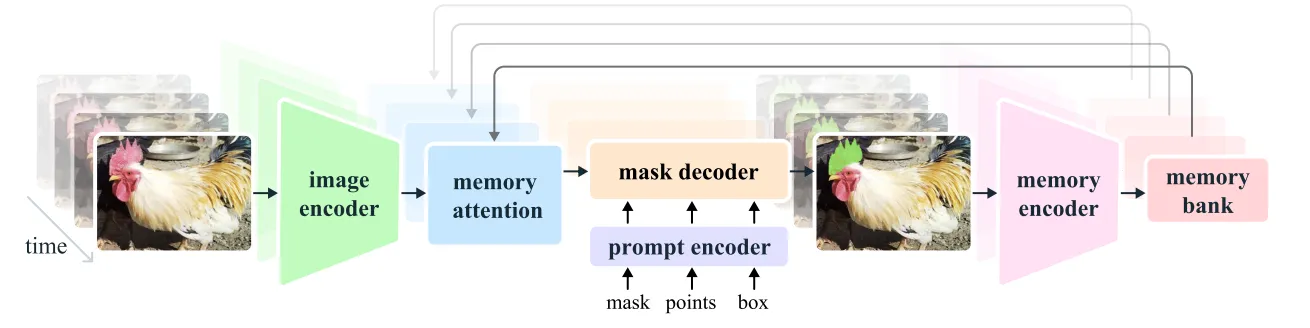
The SAM 2 architecture extends the capabilities of SAM from images to videos. It can be prompted using clicks, bounding boxes, or masks to define objects within frames. A lightweight mask decoder processes these prompts and image embeddings to generate segmentation masks. In videos, SAM 2 propagates these masks across frames, refining predictions iteratively.
A memory mechanism, consisting of a memory encoder, memory bank, and memory attention module, is introduced to accurately predict masks across all frames. For videos, the memory components store information about objects and interactions, allowing SAM 2 to generate consistent masklet predictions. The memory encoder updates the memory bank with frame-based predictions, which the memory attention module uses to condition the embeddings for the mask decoder.
The streaming architecture processes video frames sequentially, storing segmented object information in memory, allowing real-time processing of long videos. SAM 2 handles ambiguity by generating multiple mask predictions, refining them through additional prompts and selecting the most confident mask for further propagation.
Key Takeaways
Image segmentation is a cornerstone task in computer vision. Last year, Meta AI introduced the Segment Anything Model (SAM), the first foundational model for this task. Now, Meta AI has launched SAM 2, a promptable foundational model that extends segmentation capabilities to both images and videos, offering enhanced performance and versatility.

Detailed Exploration of SAM 2
Introduction
This article covers the following topics:
- Primary contributions of the SAM 2 project.
- Limitations of SAM and the improvements in SAM 2.
- SAM 2 architecture and new components.
- The SA-V dataset.
- Benchmark results.
- Running inference using SAM 2 weights.
Table of Contents
- Primary Contributions of the SAM 2 Project
- Limitations of SAM and What SAM 2 Solves
- SAM 2 Architecture
- Data Engine
- SA-V Dataset
- Comparison with SOTA VOS Models
- Real-World Use Cases
- Different SAM 2 Architectures
- Running Inference on Videos
- Summary and Conclusion
- References
Primary Contributions of the SAM 2 Project
The SAM 2 project brings three primary contributions:
- The Segment Anything Model 2.
- A new data engine for dataset preparation and evaluation.
- The SA-V (Segment Anything – Video) dataset.
Limitations of SAM and What SAM 2 Solves
SAM (Segment Anything) was initially designed for promptable image segmentation. However, it struggled with temporal data like videos, often requiring additional deep learning models for object detection in each frame. This led to significant latency in real-time applications.
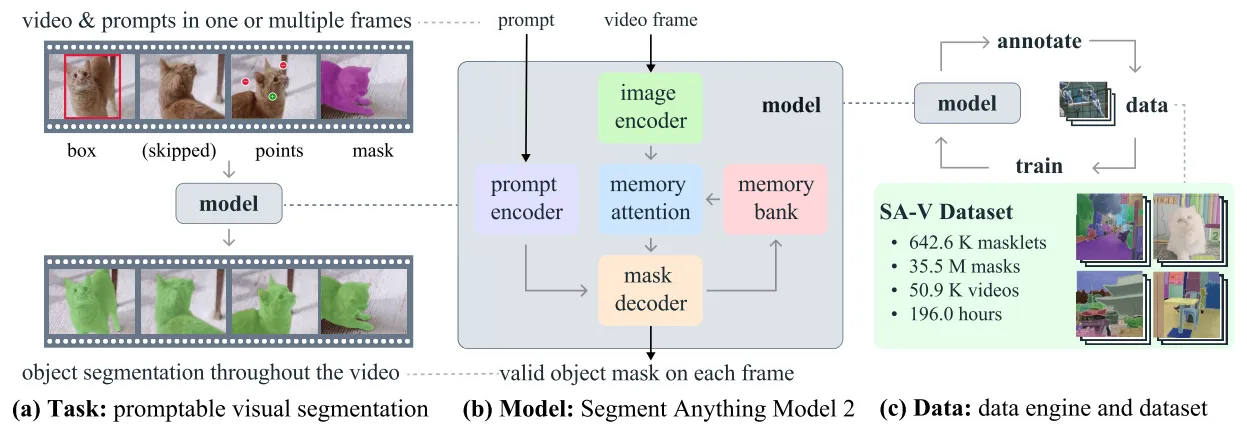
SAM 2 addresses these issues by extending the Promptable Visual Segmentation (PVS) task to videos. It allows for prompts using points, boxes, or masks on any frame, predicting objects in subsequent frames with a new training regime.
SAM 2 Architecture
The SAM 2 model generalizes the SAM architecture to the video domain. It supports prompts in three formats: points, bounding boxes, and masks. The new architecture introduces several components:
- A new image encoder.
- Memory attention for spatio-temporal data.
- Prompt encoder for handling prompts.
- A new method for mask decoding.
- A memory encoder.
- A memory bank.
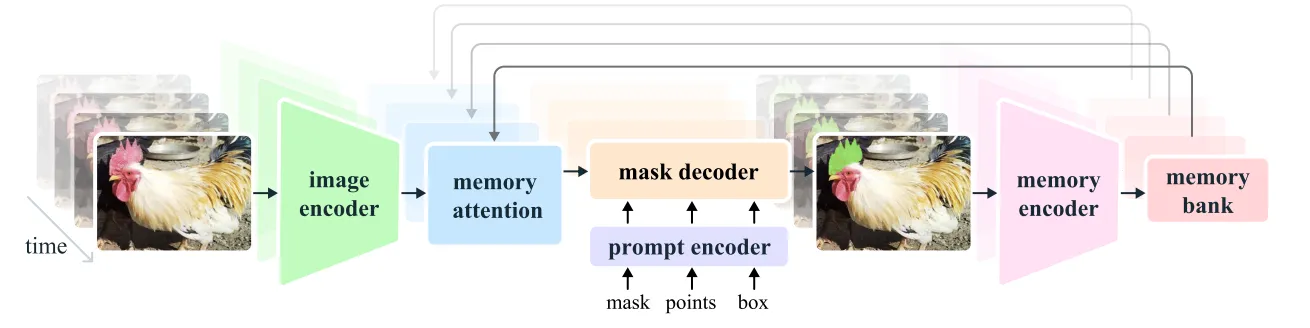
Image Encoder
The image encoder is a hierarchical masked autoencoder (Hiera), utilizing multiscale features during decoding and encoding video frames sequentially.
Memory Attention
Memory attention acts as a cross-attention mechanism, conditioning current frame features on past frame features, predictions, and prompts. This involves stacking transformer blocks.
Prompt Encoder
The prompt encoder handles different types of prompts, similar to SAM’s. Sparse prompts (points and bounding boxes) are represented by positional encodings and learned embeddings, while dense prompts (masks) are handled by convolutional layers.
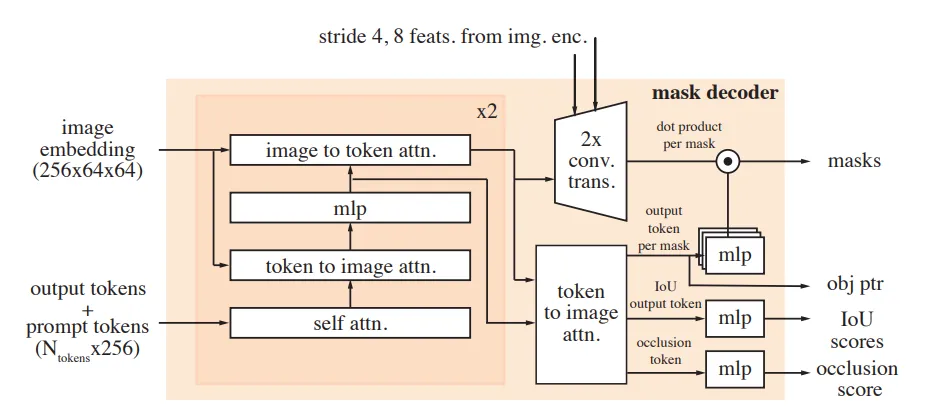
Mask Decoder
The mask decoder processes encoded prompts and frame embeddings from the memory attention module, generating masks for the current frame. A skip connection from the image encoder incorporates high-resolution information.
Memory Encoder and Memory Bank
The memory encoder stores predictions and embeddings for future use, while the memory bank keeps past predictions and prompt histories, maintaining target object information throughout the video.
Data Engine
Creating a robust model like SAM 2 requires a high-quality, diverse dataset. The data engine operates in three phases, leveraging model-in-the-loop techniques to improve annotation efficiency.
Phase 1
SAM assists human annotators in generating masks, refined manually.
Phase 2
SAM 1 and SAM 2, along with human annotators, generate spatio-temporal masklets, significantly reducing annotation time.
Phase 3
SAM 2 operates independently, requiring minimal human intervention for extreme mask refinement, generating 197K masklets.
SA-V Dataset
The SA-V dataset includes:
- 50.9K videos
- 642.6K masklets
This dataset is significantly larger than existing VOS datasets, featuring diverse scenarios across 47 countries.

Comparison with SOTA VOS Models
Although SAM 2 primarily aims at PVS, it surpasses other SOTA semi-supervised VOS models in IoU and F1 scores while maintaining real-time performance.
Real-World Use Cases
Object Tracking
SAM 2 enhances object tracking for autonomous vehicles, robotics, and special effects creation.
Cell Segmentation in Microscopic Videos
SAM 2 aids scientific research by segmenting and tracking cells in microscopic videos.
Different SAM 2 Architectures
SAM 2 is available in four versions: Tiny, Small, Base Plus, and Large. Each varies in parameters and performance.
| Model | Size (M) | Speed (FPS) | SA-V Test (J&F) | MOSE Val (J&F) | LVOS V2 (J&F) |
|---|---|---|---|---|---|
| sam2_hiera_tiny | 38.9 | 47.2 | 75.0 | 70.9 | 75.3 |
| sam2_hiera_small | 46 | 43.3 (53.0) | 74.9 | 71.5 | 76.4 |
| sam2_hiera_base+ | 80.8 | 34.8 (43.8) | 74.7 | 72.8 | 75.8 |
| sam2_hiera_large | 224.4 | 24.2 (30.2) | 76.0 | 74.6 | 79.8 |
Running Inference on Videos
Running inference using SAM 2 weights involves setting up the model and executing it on video frames, utilizing the memory attention and prompt encoding mechanisms.
Summary and Conclusion
SAM 2 significantly advances object segmentation, extending capabilities to videos with real-time performance. Its open-source release and extensive dataset encourage community innovation in video and image segmentation.
References
Refer to the official Meta documentation for detailed insights and additional resources.
Object Segmentation Evolution
Object segmentation identifies pixels corresponding to objects within an image or video frame. SAM 2 extends the foundational work of the original SAM, enabling real-time, interactive segmentation across diverse visual content. The model excels in zero-shot generalization, segmenting objects it has not previously encountered.
Real-World Impact
Since its launch, SAM has been integrated into numerous applications, from enhancing Instagram features to aiding scientific research. SAM 2 promises further advancements, enabling faster annotations for computer vision systems, creating new video effects, and supporting diverse fields like marine science, satellite imagery analysis, and medical diagnostics.
Technical Advancements
SAM 2 builds on the success of SAM by introducing several key innovations:
- Unified Architecture: SAM 2 operates seamlessly across image and video data.
- Promptable Segmentation: The model supports real-time interactive segmentation with iterative refinement.
- Memory Mechanism: Enhanced video segmentation through memory components storing object information across frames.
- Occlusion Handling: An occlusion head predicts object visibility, improving segmentation accuracy in dynamic scenarios.
SA-V Dataset
The SA-V dataset significantly expands the available annotated video data, offering:
- Over 600,000 masklet annotations across approximately 51,000 videos.
- Diverse real-world scenarios from 47 countries.
- Comprehensive coverage of whole objects, parts, and complex instances.
Results and Performance
SAM 2 demonstrates substantial improvements:
- Outperforms previous models in interactive video segmentation with fewer interactions.
- Achieves superior image segmentation accuracy while being six times faster than SAM.
- Excels in established video segmentation benchmarks, processing at approximately 44 frames per second.
Future Directions
Meta envisions SAM 2 as a component in broader AI systems, enhancing applications in augmented reality, autonomous vehicles, and scientific research. The model’s capabilities could revolutionize real-time object interaction, detailed video editing, and robust data annotation.
Conclusion
Meta invites the AI community to explore SAM 2, leveraging its open-source release and extensive dataset to push the boundaries of video and image segmentation. By fostering open science, Meta aims to drive innovation, unlocking new possibilities for technology and society.
For more details and to access the resources, visit Meta’s official release page.
Free Custom ChatGPT Bot with BotGPT
To harness the full potential of LLMs for your specific needs, consider creating a custom chatbot tailored to your data and requirements. Explore BotGPT to discover how you can leverage advanced AI technology to build personalized solutions and enhance your business or personal projects. By embracing the capabilities of BotGPT, you can stay ahead in the evolving landscape of AI and unlock new opportunities for innovation and interaction.
Discover the power of our versatile virtual assistant powered by cutting-edge GPT technology, tailored to meet your specific needs.
Features
-
Enhance Your Productivity: Transform your workflow with BotGPT’s efficiency. Get Started
-
Seamless Integration: Effortlessly integrate BotGPT into your applications. Learn More
-
Optimize Content Creation: Boost your content creation and editing with BotGPT. Try It Now
-
24/7 Virtual Assistance: Access BotGPT anytime, anywhere for instant support. Explore Here
-
Customizable Solutions: Tailor BotGPT to fit your business requirements perfectly. Customize Now
-
AI-driven Insights: Uncover valuable insights with BotGPT’s advanced AI capabilities. Discover More
-
Unlock Premium Features: Upgrade to BotGPT for exclusive features. Upgrade Today
About BotGPT Bot
BotGPT is a powerful chatbot driven by advanced GPT technology, designed for seamless integration across platforms. Enhance your productivity and creativity with BotGPT’s intelligent virtual assistance.