
bitnet.cpp: Running 100B Parameter LLMs Locally with Microsoft’s Open-Source Framework
Enhance Your Writing with WordGPT Pro
Write Documents with AI-powered writing assistance. Get better results in less time.
Try WordGPT FreeThis document explores Microsoft’s innovative open-source framework, bitnet.cpp, which enables the efficient running of 100B parameter large language models (LLMs) on standard CPUs. Traditionally, running such massive models required expensive hardware like GPUs or TPUs. However, with bitnet.cpp, high-performance LLMs can now be deployed on everyday systems, making cutting-edge AI technology more accessible.
Through 1-bit quantization and other optimizations, bitnet.cpp reduces both memory usage and computational load while maintaining lossless inference. In this article, we will dive into the framework’s features, its impact on AI development, and the practical steps for deploying it locally. Whether you’re a researcher, developer, or AI enthusiast, this guide will help you harness the power of bitnet.cpp in your projects.
Introduction
The advent of large language models (LLMs) like GPT-3 and GPT-4 has reshaped the AI landscape, pushing the boundaries of natural language processing, generation, and task automation. However, deploying these massive models traditionally requires significant computational resources, especially GPUs and TPUs. This presents challenges for developers and researchers without access to high-end hardware.
Enter bitnet.cpp, a framework developed by Microsoft that enables the efficient deployment of 100B parameter LLMs locally on CPUs, including both ARM and x86 architectures. This revolutionary approach makes LLMs more accessible, offering a new level of flexibility for those working on AI research, development, and application.
Key Features of bitnet.cpp and 1-bit LLMs
1. Local Deployment Without GPUs
Unlike traditional methods, which demand expensive GPUs or cloud infrastructure, bitnet.cpp enables the deployment of large models directly on CPUs. This reduces costs, ensures privacy, and opens up possibilities for AI projects on more widely available hardware.
2. 1-Bit Quantization for Efficiency
The framework leverages 1-bit quantization, reducing model size and computational load. This allows the BitNet b1.58 models, for example, to perform lossless inference with a fraction of the resources required for standard full-precision models. The reduced precision means faster processing times for individual predictions. This is due to the smaller size of data being processed, which translates into higher throughput and quicker response times for models in real-time applications. For AI systems needing low latency, like chatbots or personal assistants, this can significantly improve user experience.
3. Multi-Platform Support
Whether you’re on an ARM-based system like the Apple M2 or using an x86 CPU, bitnet.cpp optimizes performance across a wide range of hardware, making it ideal for a variety of devices and systems.
4. Speed and Energy Efficiency
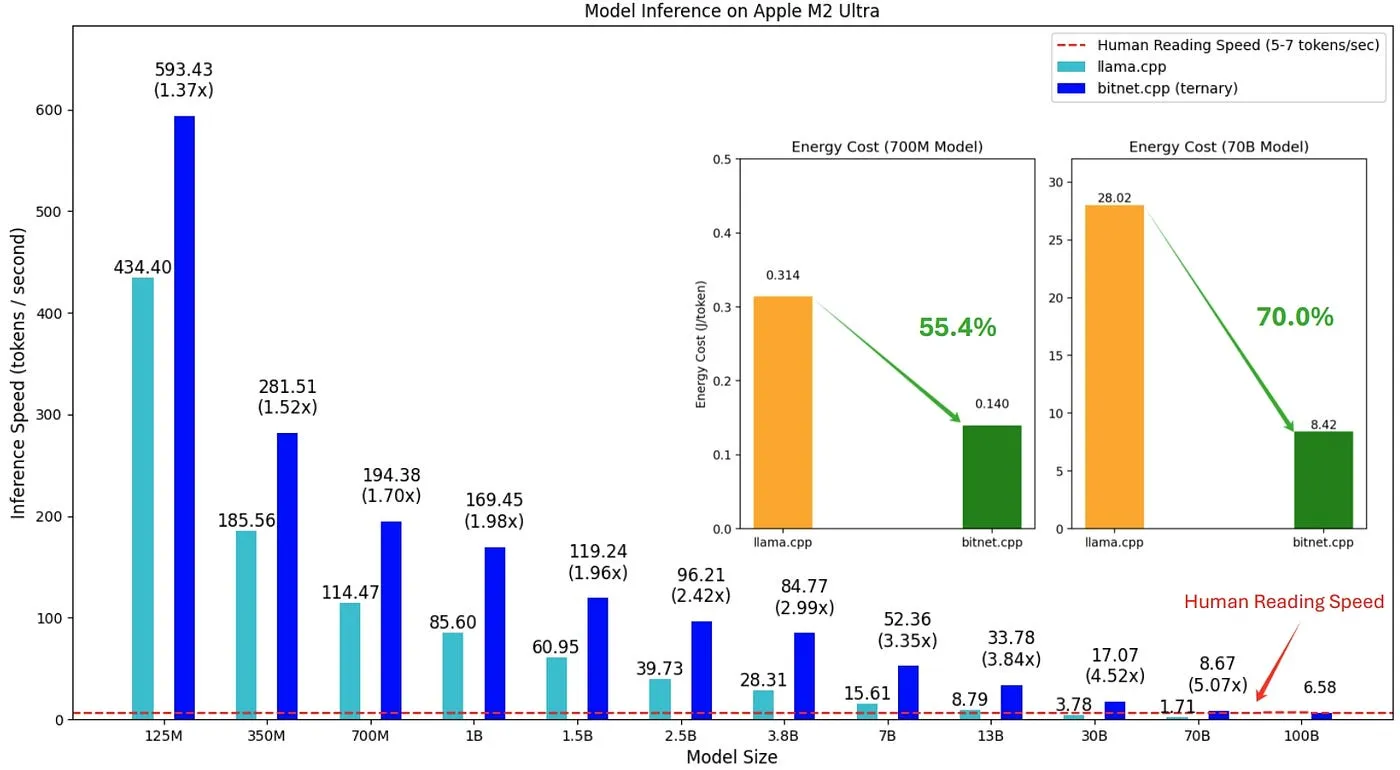
Thanks to its efficient use of 1-bit quantization and optimized kernels, bitnet.cpp offers up to 6.17x faster inference speed compared to llama.cpp and reduces energy consumption by up to 82.2% on certain systems.
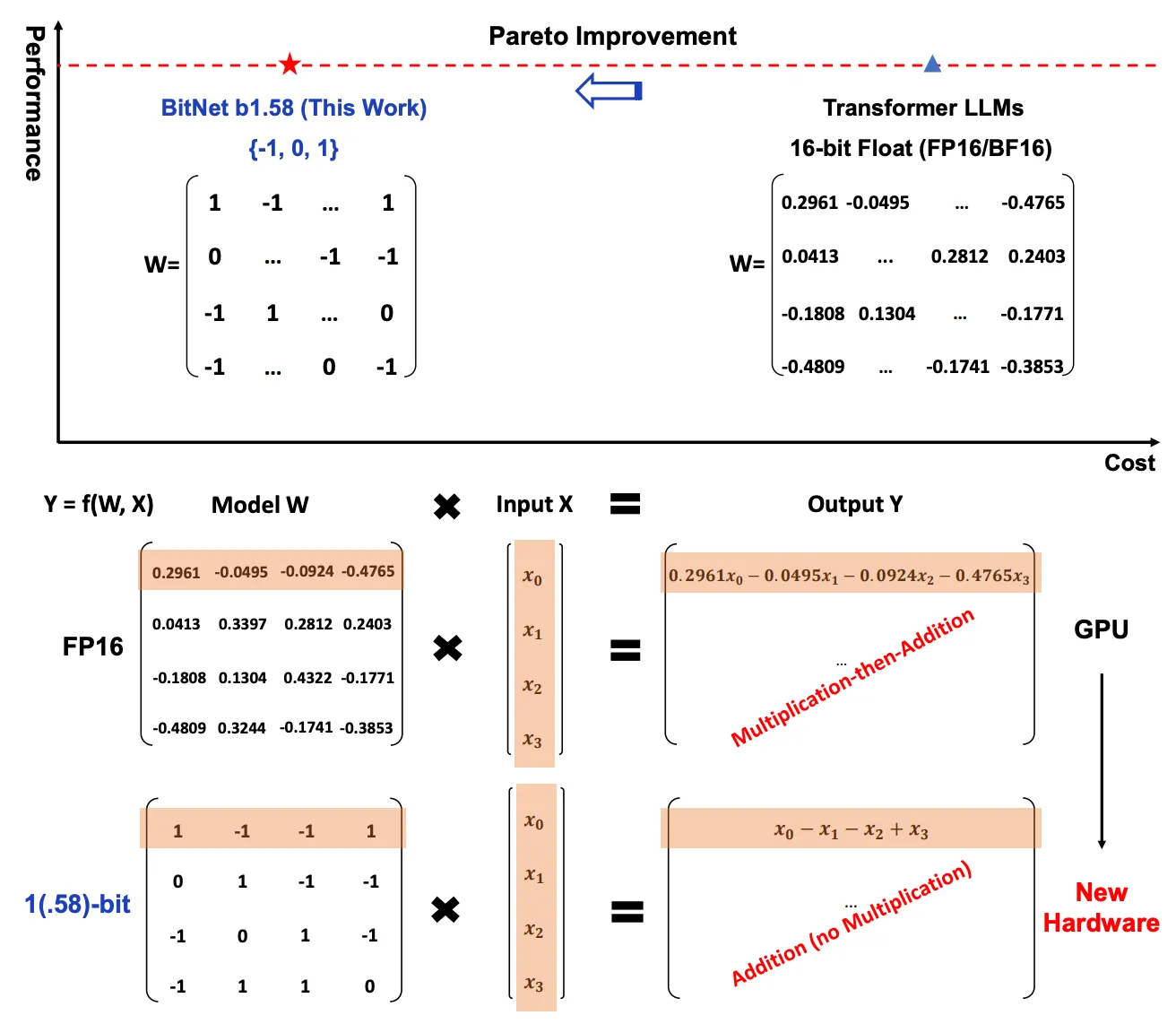
1-bit quantization reduces the precision of model weights from 32-bit floating-point numbers (FP32) to just 1-bit. This reduction results in a dramatic decrease in memory storage, bandwidth requirements, and energy consumption. Despite the lower precision, the performance degradation is often minimal, making this an ideal technique for models deployed on resource-constrained devices such as smartphones and edge devices.
5. Memory Savings
1-bit quantization allows for extreme memory savings—large models such as GPT or BERT can consume hundreds of gigabytes of memory when using full precision. By compressing these models to 1-bit precision, the required memory can be reduced by over an order of magnitude, making these models feasible for deployment on devices with limited RAM.
6. Pareto Optimality
The Pareto principle in the context of 1-bit LLMs suggests that these models offer improvements in multiple key areas (such as energy consumption and speed) without significantly compromising accuracy. By adopting 1-bit quantization, developers can achieve a balance between model efficiency and performance, opening up new opportunities for deploying complex models without the high operational costs typically associated with large-scale AI systems.
7. Scalability and Deployment
1-bit LLMs offer a practical solution to scaling large language models. They allow organizations with limited computational resources to deploy high-performing models on a larger scale. By dramatically reducing both costs and hardware requirements, 1-bit quantization makes it possible to scale AI applications and make them more widely accessible.
Performance Highlights
Speed Comparison
| Model Size | llama.cpp (Tokens/sec) | bitnet.cpp (Tokens/sec) | Speedup |
|---|---|---|---|
| 13B | 1.78 | 10.99 | 6.17x |
| 70B | 0.71 | 1.76 | 2.48x |
Energy Efficiency
- ARM (Apple M2 Ultra): Up to 70% lower energy usage
- x86 (Intel i7-13700H): Energy savings of 71.9% to 82.2%
How bitnet.cpp Works
1. 1-Bit Quantization
At the core of bitnet.cpp is 1-bit quantization. This process compresses model weights into 1-bit representations, which significantly reduces memory requirements while maintaining the accuracy of predictions.
2. Optimized Kernels
The framework employs optimized computation kernels to manage data flow and optimize performance:
- I2_S Kernel: Designed for high-performance threading in multi-core CPUs.
- TL1 Kernel: Enhances memory access patterns and optimizes lookup efficiency.
- TL2 Kernel: Focused on environments with tight memory or bandwidth restrictions.
3. Model Compatibility
bitnet.cpp supports a wide range of models, from smaller ones like LLaMa to massive 100B parameter configurations. Its flexibility makes it adaptable to various use cases and systems.
Getting Started with bitnet.cpp
Step 1: Clone the Repository
git clone --recursive https://github.com/microsoft/BitNet.gitcd BitNetStep 2: Set Up Your Environment
conda create -n bitnet-cpp python=3.9conda activate bitnet-cpppip install -r requirements.txtStep 3: Download and Quantize the Model
python setup_env.py --hf-repo HF1BitLLM/Llama3-8B-1.58-100B-tokens -q i2_sStep 4: Run Inference
python run_inference.py -m models/Llama3-8B-1.58-100B-tokens/ggml-model-i2_s.gguf -p "Enter your prompt here."Demo Video
Watch the video to see BitNet in action:
Conclusion
bitnet.cpp is a powerful tool that unlocks the potential of large language models without the need for expensive GPUs or cloud computing resources. By leveraging 1-bit quantization and other optimizations, Microsoft’s open-source framework delivers fast, efficient, and cost-effective AI deployment. Whether you’re working with smaller models or scaling up to 100B parameters, bitnet.cpp makes it easier than ever to harness the power of AI on standard CPUs.
- 🔗 Explore the Code: bitnet.cpp on GitHub
- 📄 Read the Paper: 1-bit AI Infra: Fast and Lossless BitNet Inference
What’s Next?
As AI continues to evolve, frameworks like bitnet.cpp will play a pivotal role in democratizing access to powerful models. The future of AI is about making cutting-edge technology accessible to everyone, and bitnet.cpp is paving the way for this exciting transformation.
Free Custom ChatGPT Bot with BotGPT
To harness the full potential of LLMs for your specific needs, consider creating a custom chatbot tailored to your data and requirements. Explore BotGPT to discover how you can leverage advanced AI technology to build personalized solutions and enhance your business or personal projects. By embracing the capabilities of BotGPT, you can stay ahead in the evolving landscape of AI and unlock new opportunities for innovation and interaction.
Discover the power of our versatile virtual assistant powered by cutting-edge GPT technology, tailored to meet your specific needs.
Features
-
Enhance Your Productivity: Transform your workflow with BotGPT’s efficiency. Get Started
-
Seamless Integration: Effortlessly integrate BotGPT into your applications. Learn More
-
Optimize Content Creation: Boost your content creation and editing with BotGPT. Try It Now
-
24/7 Virtual Assistance: Access BotGPT anytime, anywhere for instant support. Explore Here
-
Customizable Solutions: Tailor BotGPT to fit your business requirements perfectly. Customize Now
-
AI-driven Insights: Uncover valuable insights with BotGPT’s advanced AI capabilities. Discover More
-
Unlock Premium Features: Upgrade to BotGPT for exclusive features. Upgrade Today
About BotGPT Bot
BotGPT is a powerful chatbot driven by advanced GPT technology, designed for seamless integration across platforms. Enhance your productivity and creativity with BotGPT’s intelligent virtual assistance.